stable diffusionが公開されてから1ヶ月で、waifu diffusionやTrinArtなど、美少女生成に重点を置いたモデルが登場し、当初はpython環境を自前でインストールする必要があったStable diffusionも、AUTOMATIC1111やNMKD GUIの登場によって、簡単に環境が構築できるようになりました。
私の環境について 生成をスムーズに行うため、VRAM24GBの、GeForce RTX 3090を使用しています。
RTX3090ですが、後継モデルのRTX 4090がまもなく登場することもあり、かなり安価になっていますので、お買い得になってきたと思います。
VRAMの容量がどのように影響してくるかというと、生成可能な画像サイズに関係します。
では、早速美少女を作る方法に移りたいと思います。
https://huggingface.co/hakurei/waifu-diffusion
ダウンロードしたckptファイルを、model.ckptにリネームし、AUTOMATIC1111であれば\cache\models\model.ckptに設置すれば利用可能になります。
1,参考になるpromptを探す 自力でpromptを作るよりも、良さそうなものを探すのが早いです。
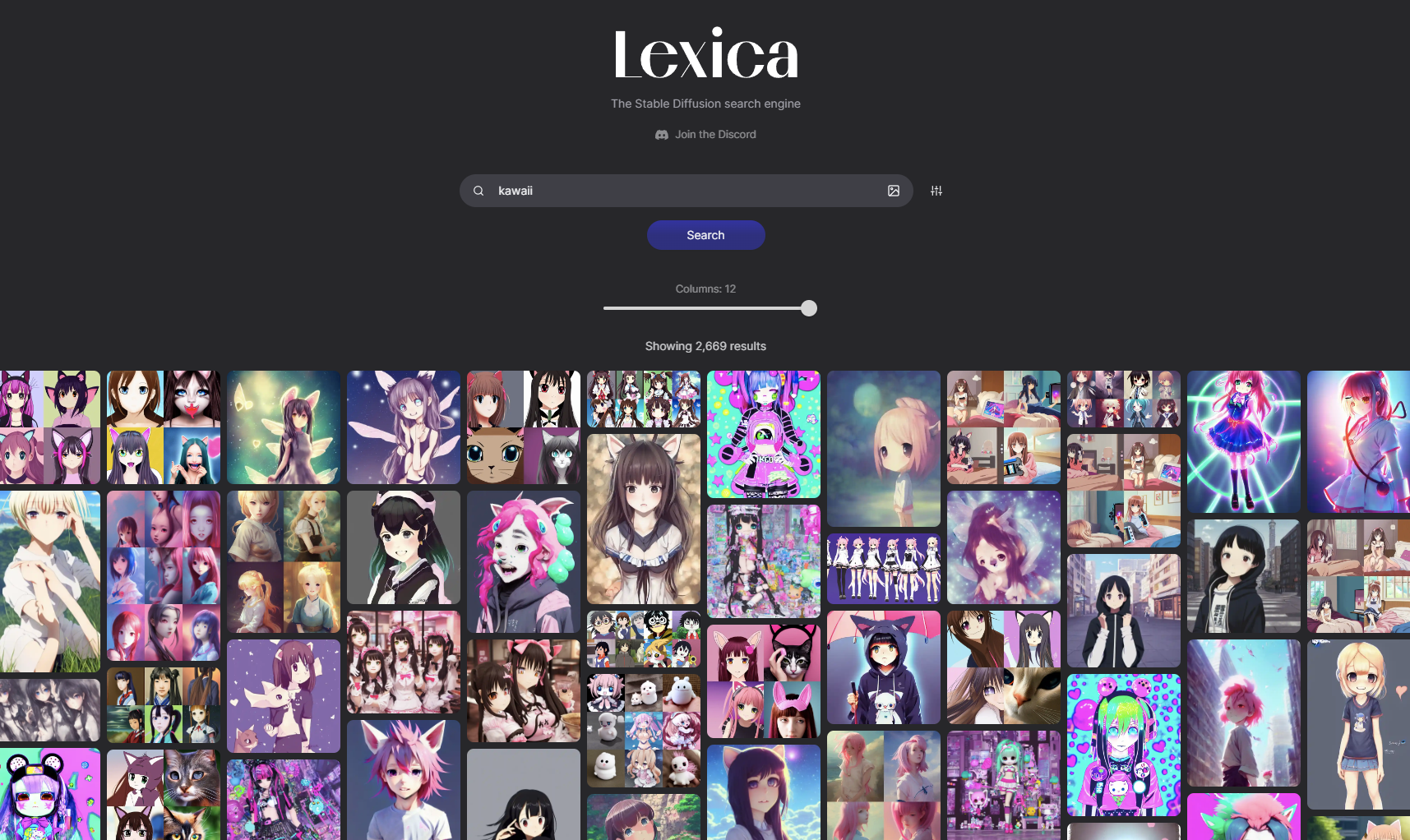
https://lexica.art/
ただ、このサイトはStableDiffusionのmodelで生成されているサンプルになりますので、WaifuDiffusionで出力するとかなり雰囲気が変わるので注意です。
「kawaii」と入力して検索すると、大量のカワイイ画像が表示されます。
この中から、好みの絵を探してみてください。
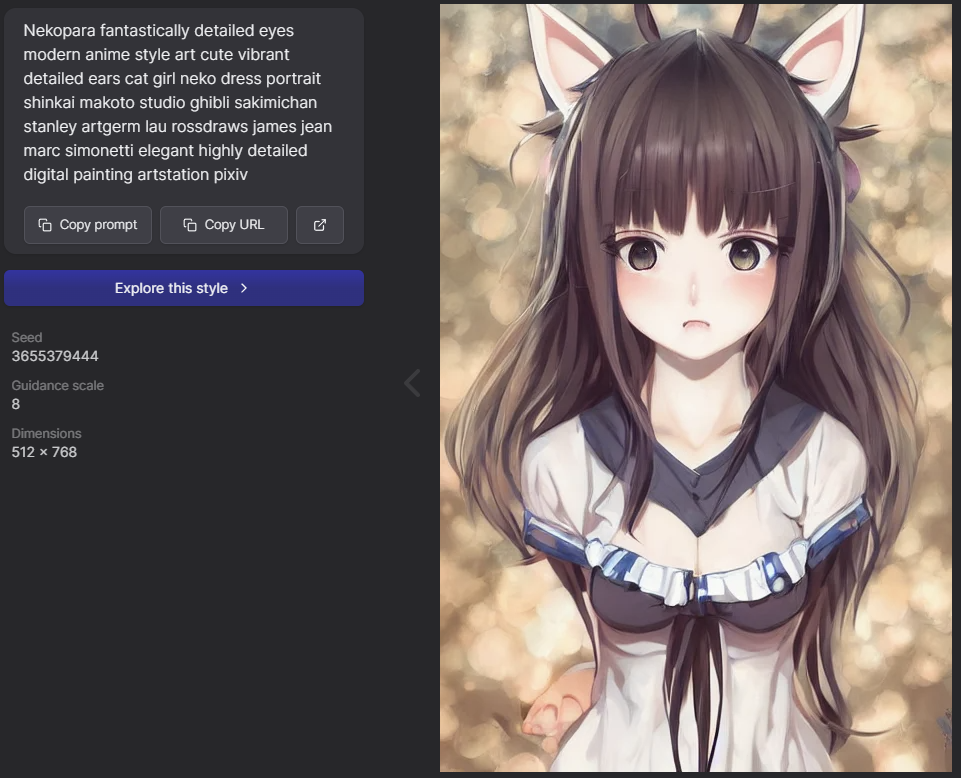
promptですが、以下の通りです。
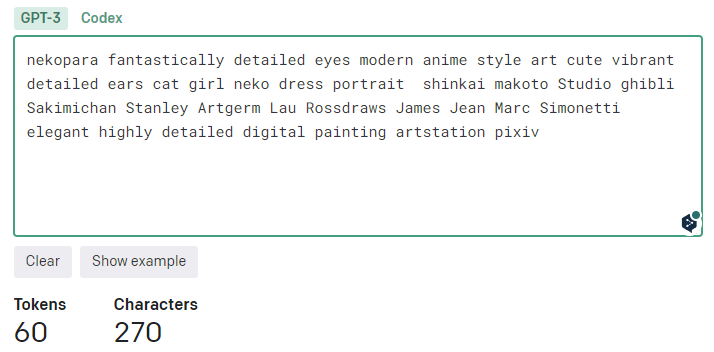
nekopara fantastically detailed eyes modern anime style art cute vibrant detailed ears cat girl neko dress portrait shinkai makoto Studio ghibli Sakimichan Stanley Artgerm Lau Rossdraws James Jean Marc Simonetti elegant highly detailed digital painting artstation pixiv
2,promptの文字数をチェックする StableDiffusionのtxt2imgは、文字から画像を生成する仕組みですが、文字(Prompt、呪文)には長さ制限があります。
トークンをチェックするのに便利なのが、OpenAI APIというサイトです。
https://beta.openai.com/tokenizer
試しに、先ほどのPromptをチェックしてみましょう。
トークン数は60と出ました。
3,まずはそのまま生成テストしてみる どのような画像が生成されるか、テストしてみます。
高解像度(目安として、長辺が700ピクセル以上)で出力する場合、人物が分離してしまう傾向があります。
samplingを20にして、5枚出力してみました。https://twitter.com/tkaz2009/status/1572155308621074437
なにかよくわからない生物が映り込んでいる画像もありますね…。
nekopara fantastically detailed eyes modern anime style art cute vibrant detailed ears cat girl neko dress portrait shinkai makoto Studio ghibli Sakimichan Stanley Artgerm Lau Rossdraws James Jean Marc Simonetti elegant highly detailed digital painting artstation pixiv
となります。
4,要素を足したり引いたりして、好みの画像に近づける それなりに可愛い画像が生成されましたので、好みの画像に近づけていきましょう。
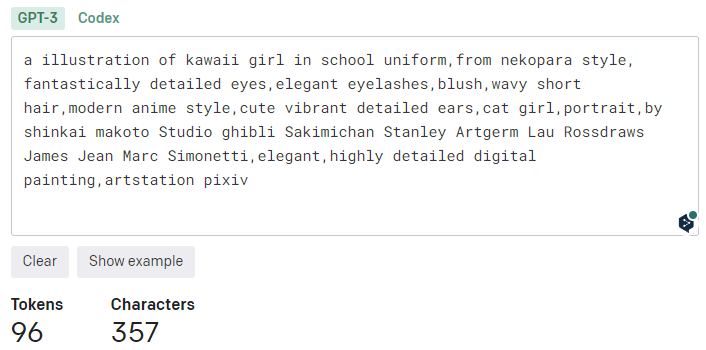
イラストっぽくするため、頭にa illustration of kawaii girlを追加します。
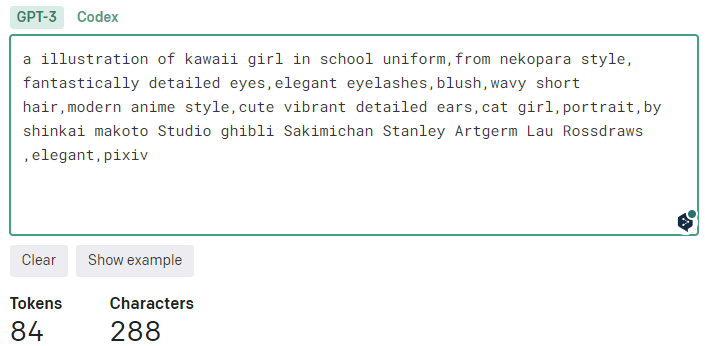
promptをいじる際は、先ほどのOpenAI APIでトークン数をチェックすると良いです。
だいぶいろいろ変わりました。
a illustration of kawaii girl in school uniform,from nekopara style, fantastically detailed eyes,elegant eyelashes,blush,wavy short hair,modern anime style,cute vibrant detailed ears,cat girl,portrait,by shinkai makoto Studio ghibli Sakimichan Stanley Artgerm Lau Rossdraws ,elegant,pixiv
実際に試す場合は、上のpromptをコピペしてください。
一気に雰囲気変わりましたね。
とりあえず5枚出力してみましたが、一番右の、シードが3854870818が良さそうです。
このように、画像のシード値を指定し、samplingを100にして、1枚生成してみます。
うう…可愛くない。
おお、一気に可愛くなりましたね。
このように、samplingとCFG scaleだけでもかなり印象が変わる上に、Highres.fixを使っている場合、Denoising strengthの値によってもだいぶ変わってきます。
sampling
CFG scale
Denoising strength
といった感じで指定しています。