無料公開されたStable Diffusion、至る所で話題になってますね。
私も早速Windows11環境に導入してみました。
NVIDIAのビデオカードを使っているPCがあれば、ローカル環境で動かすことが可能です。
※ビデオカードが無くても大丈夫な方法もありますが、割愛。
導入方法ですが、仮想環境を使う、anacondaをインストールして使うなどいろいろな方法がありますが、一番簡単な方法は下のリンクにある方法でした。
ZIPアーカイブをDLして解凍、あとは若干の作業で動かすことができます。
gitでの操作が必要ですが、git for Windowsをインストールして、git clone URL…でソースコード一式をDL可能ですので、複雑ではありません。
img2imgとその他全部盛りのツールをローカルで動かそう[StableDiffusion]
私のPCは以下の環境となります。
- Core i7-12700KF
- GeForce GTX1080(VRAM 8GB)
- Windows11
エラーが出るときは
Promptの一部をフォルダ名にしているため、Windowsのパスの文字制限に引っかかってしまうことがあるようです。
その場合は、以下の方法で文字制限を解除できますので、お試しください。
テキスト(Prompt)で絵を描いてみる
Stable Diffusionですが、絵を描くのに2つの方法があります。
txt2img:Promptと呼ばれるテキストを元に絵を生成する
img2img:元になる絵にPromptのテキストを適用し絵を生成する
サンプルを元に、見ていきたいと思います。
まずは、Promptと呼ばれるテキストで絵を描いてみましょう。
Promptは慣れが必要ですが、以下のサイトを見つつ、気に入った絵を出力するPromptを元に、テキストを入れ替えてみるのがいいと思います。
とりあえず、生成した結果を見ていきましょう。
使用したPromptは以下となります。
A princess with silver hair and black gothic lolita dress, fairy tale style background, a beautiful half body illustration, top lighting, perfect shadow, soft painting, reduce saturation, leaning towards watercolor, art by hidari and krenz cushart and wenjun lin and akihiko yoshida,highly detailed, elaborate, digital painting hyper quality
上記で、どのような絵が生成されるかというと…







すげえですな…。
ちなみに、Promptでどんな指定をしているかというと、
A princess →女性キャラクタ。girlでもいいけど、princessの方が好印象な場合が多いっぽい
with silver hair →髪の毛の色指定
and black gothic lolita dress, →服装指定
fairy tale style background, →背景指定。妖精っぽい感じ。なので、たまに羽根が付いている絵が。
a beautiful half body illustration, →上半身を中心としたイラスト
top lighting, →照明指定
perfect shadow, →影生成指定
soft painting, reduce saturation, →画質指定
leaning towards watercolor, →色味指定
art by hidari and krenz cushart and wenjun lin and akihiko yoshida, →絵師などを指定すると絵柄が寄る
highly detailed, elaborate, digital painting hyper quality →画質指定
といった感じです。
Promptの指定については、以下のサイトが参考になります。
AI画像生成ツール「Stable Diffusion」のコツまとめ(text2image)
Deepl(英語翻訳用)
ちなみに、Stable Diffusionは正方形で学習しているようで、作成する寸法も正方形が一番精度が高いようです。
画像を元に絵を描いてみる
指示用のラフ絵を元にイラストを生成している記事は多数ありますので、ちょっと方向を変えて、自作のイラストを別のテイストにできるか実験してみました。
指示用のラフから好みの絵を作成する方法は、下のサイトがわかりやすいです。
Stable Diffusionのimg2imgで好みの絵を作成するまでの過程
ラフの線画を加工してみる
20年以上前に描いたイラストがあるので、引っ張り出してみることに。
テストで使ったのは、以下の画像になります。
さて、こいつを元に適当にPromptを設定して生成してみると…




おおお…手書きのタッチまで再現されてますよ!すげえ!
しかも、オリジナルより可愛くなってきる気もする…!!
服の一部が髪の毛になったり、腕が怪しいことになっていたりしますが、それにしても凄いですね。
着色したラフ画を加工してみる
お次は、ラフに着色したこいつを。

コツは、Classifier Free Guidance Scale (how strongly the image should follow the prompt)を強く設定するとペン入れしたような絵柄になり、低く設定するとラフスケッチの線画がそのまま生きた状態になります。
さて、この絵にもPromptを設定して生成してみると…



なんと…一部怪しくなってるパーツもありますが、レースやヘッドドレスの細かさが半端ない!
ちなみに、カチューシャではなく花のヘッドドレスになっているのは、Promptにflower bloomingを指定している影響と思われます。
適当に手を抜いて描いたフリルがすごい細かくなってるし、ストッキングの質感がまた素晴らしい…。
いやあ、楽しい。
20年以上前のイラストでも、AI処理すれば今時っぽくなるものですなぁ…。
ポーズ人形をイラストに変換してみる
お次の実験は、こちら。

イラストを描く際の強い味方、ポーズ人形。
これをimg2imgで、一気にイラストにしてみたいと思います。





これは…!
ポーズ人形を用意しておき、好きなポーズにして写真を撮って、Stable Diffusionで処理するだけで、いろんなイラストが出力されてしまうとは…恐るべし。
しかも、衣装もいろんなバリエーションがあって面白いですね。
このあたりはPromptを設定するといろいろいじれそうです。
しかし…一番左側のイラストとか、AIが一発生成したとは思えないレベルです。
腕のポーズが異なっているのは、Denoising Strengthを強めに設定したことで、元のポーズ人形と比べて自由度があるためです。
Denoising Strengthを弱め(0.4とか)に設定すると、同一ポーズの画像のみが生成されます。
なお、生成した際のPromptですが、最初に説明しているサイトで紹介されているものを使うと、画像と同じフォルダにyamlファイルが生成され、その中にテキストとして記録されていますので、後から同じ設定で画像を生成する際に便利です。
それにしても、Stable Diffusion、恐るべし…!
Prompt指定個人的メモ
メモっておかないと忘れるので…。
アニメ風にするか、3D風にするかは服装によっても異なってくる
たとえば、服装の指定のみ変更したPromptで生成した以下2枚ですが、かなり雰囲気が異なります。


かなり極端な画像を抽出していますが、左は「white silk Ruffled apron, white silk Ruffled Skirts,
black Maid Clothes, black Ruffled Headdresses, Knee-Length Long black Skirts」、右は「silver hair and black gothic lolita dress」を指定して生成したもの。
おそらくですが、Maid Clothesを入れると、いわゆる“メイドさん”のイラストが多く、よりアニメ絵に引っ張られるような気がします。
あとは、服装を指定する語が多すぎて、後ろのほう(60語を超えたあたり?)は無視された結果かもしれませんが…。
出力サイズを大きくするならRealESRGANを使おう
VRAM8GBの環境では、576×576px程度の出力が限界です。
画像を引き伸ばすのであれば、Upscale images using RealESRGANにチェックを入れると、大きめの解像度の画像が出力されます。
その際、Save individual imagesにチェックが入っているとオリジナルサイズも出力されてしまうので、こちらのチェックは外しておきましょう。
※RealESRGANは別途インストールが必要です。
Stable Diffusionを使うには、最低VRAM8GBは欲しい
Stable Diffusionを使うには、NVIDIAのビデオカードがほぼ必須なのは、最初に説明したとおりです。
これは、AIの処理にNVIDIAのビデオカードの機能を使っているためで、ATIのビデオカードでは残念ながら動作不可となります。
私はGeForce GTX1080でStable Diffusionを使っていますが、8GBのビデオメモリだと512×512pxの画像を出力するのでほぼギリギリです。
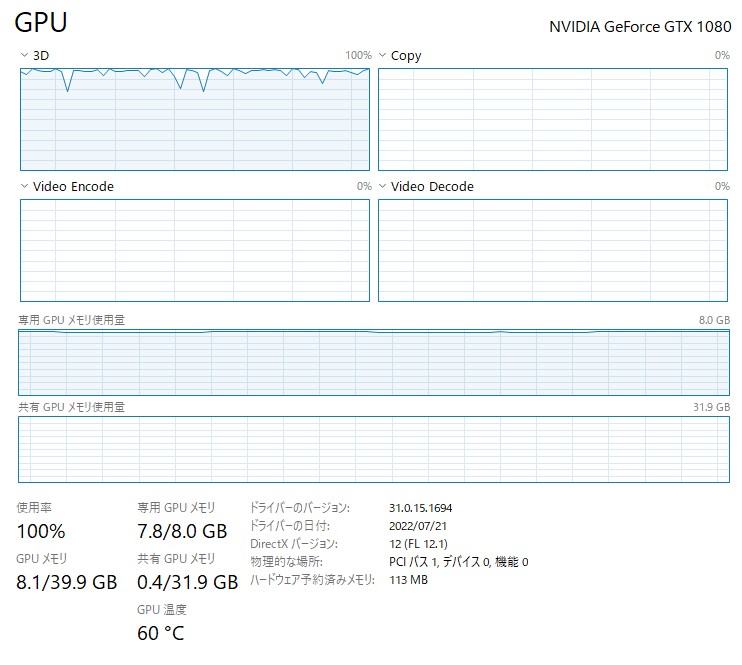
出力処理中のGPUリソースですが、ビデオメモリがほぼ100%使っているのがわかります。
VRAM容量をオーバーするとエラーを出して止まってしまいます。
Stable Diffusionを使い倒すのであれば、できれば12GBのビデオメモリを搭載したビデオカードが欲しいところです。
いろいろなテイストの絵を描かせてみる
今まで生成したイラストのうち、気に入っているものをご紹介。
主に、LexicaやTwitterなどで公開されている呪文を軸に、ワードの入れ替え、追加を行って生成しています。



どれも同一Prompt。2枚目は、顎が角張っていたので修正しています。
両方とも同じPromptから。有名なアーティストの方のTwitter IDが指定されているので、変更することで絵柄を変えられそうです。
顔を整える部分は応用が利きそう。
同じPromptで、横長にしてみたのがこちら。



絵柄の安定っぷりが恐ろしい…
アーティスト指定は絵柄が安定する反面、そのまんまの部分があるので、AIに描かせるという点では卑怯かもしれません。



1枚目は、顔と腕に加筆してますが、かなり気に入っている1枚です。
生成Promptとseedは保存してあるので、解像度あげて生成してみますか。
ちなみに、縦横比を変えると、全く別物の画像になってしまうので要注意です。



もう少し、アニメ塗りっぽくしてみたのがこちら。
フリルがなんともたまりません。